开云世界杯(中国)有限公司 AI大模子期间, 什么是蒸馏? 什么是常识蒸馏?
发布日期:2026-06-17 22:20 点击次数:76

平方的东说念主改变弃世,优秀的东说念主改变原因,顶级能手改变模子
你应该嗅觉到了,手机里的AI助手好像“开窍”了,比以前“灵敏”点了。
以前,你问Siri、小爱同学“今天天气怎么样”,它要转圈、联网,偶然刻还绪论不搭后语。
咫尺,你断网喊它定个闹钟,它秒回。你写周报,AI帮你回归数据,险些无谓等。你开车,车机我方识别东说念主行说念,刹车比你还粗心……。
你有莫得想过:为什么?
其实,不是你的网速变快了,也不是手机芯片性能翻倍了,而背后藏着一个你可能听过,但还没搞懂的技能——常识蒸馏。
它有点像“熬高汤”,把一大锅食材熬成一碗浓汤,体积小了,但精华都在。
常识蒸馏,即是在作念这样的事儿——把大模子的“灵敏劲儿”浓缩进一个小模子里,然后塞进你的手机、腕表、汽车等电子建造中。这样的话,即使断网,它们也颖悟活,秒回不卡顿。
今天,就和人人聊聊“常识蒸馏”这个话题。但愿小伙伴们阅读后,能有点收货。
1、什么是常识蒸馏?
陈述这个问题前,我们先搞懂:什么是蒸馏。
来,先看张图,你细目老成。
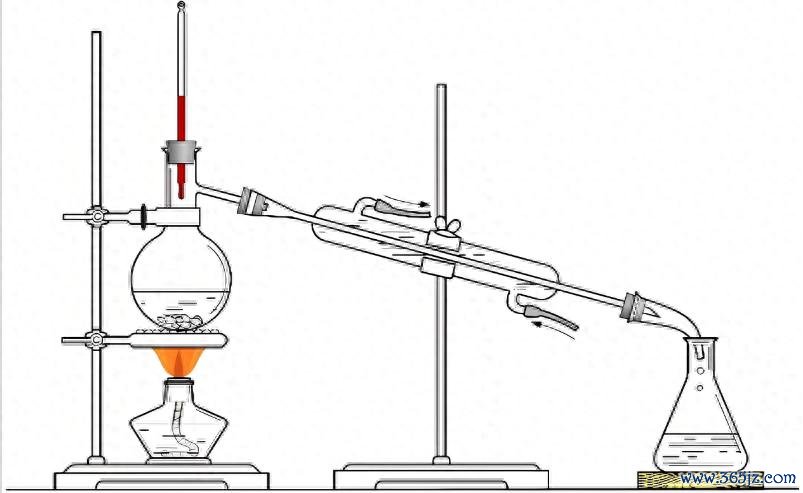
对,没错,这即是“实验室制取蒸馏水”。
没见过?不巨大,我再说个画面,你细目见过。
一口大锅里熬着骨头汤,灶火冉冉煨着,水汽蒸腾,临了锅里的汤从一大锅变成一小碗。尝一口,比正本的汤浓十倍。
为什么?
因为水分挥发掉了,留住来的全是骨头里的胶质、脂肪、香味——最精华的东西。
这即是蒸馏的施行:去除过剩的水分,保留最中枢的养分。
其实,常识蒸馏,干的是访佛的事情。只不外,它的“锅”是一台大模子,它的“骨头”是海量的参数和数据,它的“汤”是模子学到的判断才和谐想考边幅。
是以,常识蒸馏,即是用一个很犀利的大模子当憨厚,把它的“想考流程”提取出来,教给一个小模子当学生。学生学完后,体积小、跑得快、省电,还能不联网干活。但它的灵敏进度,跟憨厚差未几。
简便说,常识蒸馏,即是把大模子这些复杂的“领略精华”,提取出来,浓缩进一个小模子里。
你可能会问:平直把大模子塞进手机里,不就行了?
天然不行。大模子太“重”了,一个GPT-4级别的模子,参数几千亿,体积几百个GB,手机根底装不下,就算装下了,跑一次要几秒钟,你等不起。并且它还高出耗电,跑几分钟手机就发烫。
是以,科学家才想了“蒸馏”这个主义:不让大模子亲身干活,让它当憨厚,把我方的关节“教”给一个小模子。小模子学完之后,就可以去手机、电脑、汽车内部干活了。
你可能又要问:这是怎么作念到的?
这样,你记忆一下我方上学时,学霸是怎么给你讲题的。
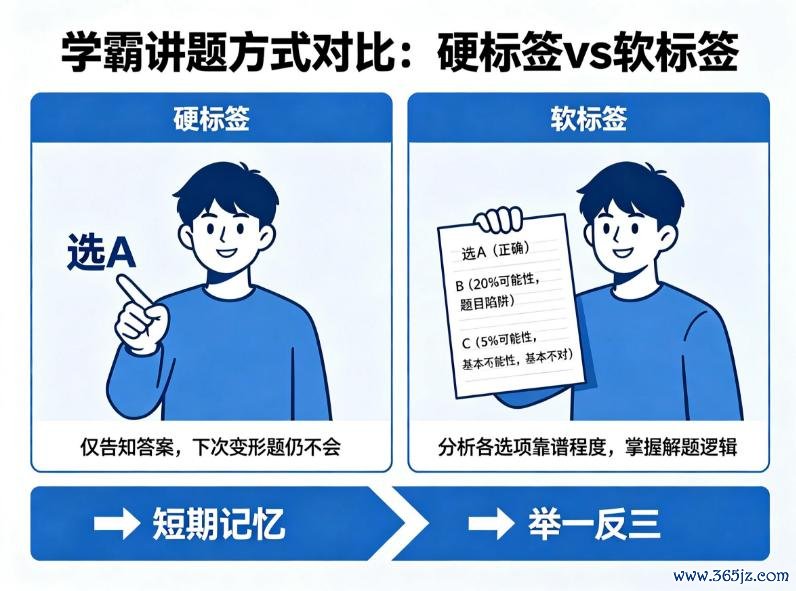
第一种情况:学霸平直告诉你“选A”,你记着了谜底。但下次遭受这说念题的变形题,你依然不会。这叫硬标签。
第二种情况:学霸不光说选A,还分析“A正确,但B也有20%的可能性,因为题目里有个罗网;C惟有5%,基本不合。”他把每个选项的“靠谱进度”都讲给你听。这叫软标签。
你听完第二种,不仅知说念谜底,还知说念“B错在哪”、“C什么时刻可能对”。以后即便遭受变形题、新题,你也能举一反三。
常识蒸馏,访佛第二种情况。
开云kaiyun中国官网入口憨厚模子(大模子)濒临一个问题,会给出一个概率散播:A有90%,B有7%,C有2%,D有1%。这个散播里藏着憨厚模子的“想考萍踪”——哪些谜底赫然对,哪些沾点边,哪些是罗网。学生模子(小模子)学的不是单一谜底“选A”,而是学这个概率散播——学“为什么B有7%的可能性”。这样一来,小模子诚然脑子小,但想问题的边幅接近大模子。
你的问题又来了,为什么非要学“概率散播”?
因为,现实宇宙很少有独一的正确谜底。你问AI“周末去哪玩”,它若是只给你一个谜底,能够不是你要的。
好的谜底,常常是在几个选项中衡量出来的。
小模子学了概率散播,就知说念“在什么情况下选B,在什么情况下选C”,遭受新问题也能举一反三。
是以,你看,常识蒸馏的施行:不是让模子变小,是让模子变灵敏的边幅不变。
2、为什么大模子期间离不开蒸馏?
咫尺我们知说念了:常识蒸馏即是让大模子当憨厚,把小模子教灵敏。
你可能想问:“蒸馏技能”不是早就有了吗?怎么这两年倏得到处都在提?
没错,常识蒸馏的办法2015年就提倡了。但其时刻的AI模子,还没这样大,算力也没这样贵,人人不认为它是“必需品”,也就没怎么提。
大模子期间来了之后,一切都不一样了,矛盾点立马凸显。
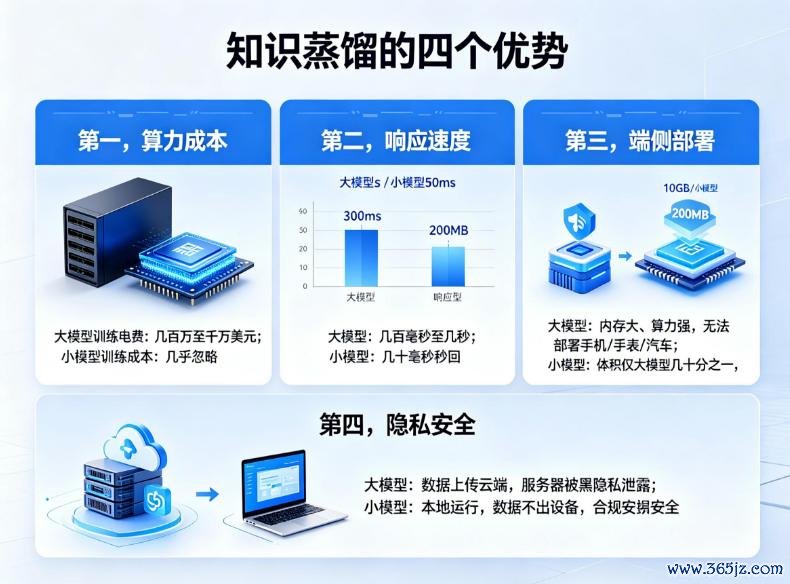
第一,是算力老本。
据机构测算,考试一个GPT-4级别的大模子,一次电费约几百万致使上千万好意思元。而蒸馏后的小模子,考试老本险些可以忽略。据报说念,微软用蒸馏后的小模子Phi-3-mini替换了部分场景中的GPT-4,老本大幅下落。
因此,当你的模子大到一定进度,算力老本重压下,蒸馏就不是选拔题,是生计题。
第二,是反应速率。
大模子跑一次几百毫秒致使几秒,你问它一句话,转圈半天才回。而小模子几十毫秒出弃世,险些秒回。
要知说念,在及时对话、自动驾驶这些场景里,几秒的延伸是齐全不可选用的。倒不是蒸馏更好用,而是慢的让你根底用不了。
你等得起的,用户等不起,你慢,他们立马就换。
第三,是端侧部署。
你的手机、腕表、汽车等电子建造,内存小、算力弱,根底装不下大模子。但用户想要的是离线也能用的AI,不想什么都上传云霄。
常识蒸馏后的小模子,体积惟有大模子的几相配之一,可以无礼塞进建造里。据报说念,苹果通过蒸馏技能将谷歌的Gemini模子才调移动到iPhone端,杀青腹地运行。
第四,是隐讳安全。
以前AI靠云霄,你的语音、相片都得上传,万一办事器被黑,隐讳全裸奔。欧洲的GDPR、中国的《个东说念主信息保护法》,都在收紧数据出境的截止。蒸馏让AI在腹地运行,数据不出建造,既合规又安全。
你的机密,惟有你和手机知说念。
是以,常识蒸馏不是倏得“被拿起”的,而是大模子期间把上头这几个矛盾,同期推到了台前,且不得不科罚。而常识蒸馏,正好是能化解这些矛盾点。
也即是说,莫得蒸馏,大模子基本上只可在实验室里当胪列。
3、蒸馏为什么能让小模子学到大模子的“真关节”?
要陈述这个问题,那就不得不先说两个办法:温度T、暗常识。
这是什么玩意?
哎,等下,先别划走。这两个词听起来像玄学,其实是蒸馏内部最中枢的两个办法。
搞懂它们,你就能透彻理会:蒸馏为什么能让小模子学到大模子的真关节。
前边我们说,大模子当憨厚,要把我方的概率散播教给小模子。但你有莫得想过这个问题:偶然刻,大模子输出的概率散播,常常太“自信”,小模子常常会学偏。
什么酷爱?
举个栗子。
大模子判断一王人题,可能输出:A有90%,B有7%,C有2%,D有1%。这个散播自己没错,但小模子一看:A 90%遥遥最初,B、C、D险些可以忽略。于是,开云世界杯(中国)有限公司小模子就会认为“归正B、C、D基本无谓管”,弃世它只学会了选A,没学会B和C到底差在哪。
这即是“大模子太自信,小模子学跑偏”。
科学家为了科罚这个问题,引入了一个叫“温度T”的参数。调高温度,可以让大模子的概率散播变得更“平滑”。
正本90%、7%、2%、1%的散播,调高温度后可能变成70%、20%、8%、2%。这样一来,B、C、D的各别就显出来了,学生能了了地看到:正本B也有一定酷爱,C偶尔也对,D基本没戏。
另外,那些被正确谜底“压下去”的低概率可能,有一个绝顶的名字叫暗常识。而这些暗常识之是以热切,是因为它们常常是AI着实长入复杂宇宙的钥匙。
举个栗子。
假定你教一个小孩认动物。你给他看一张猫的图片,说“这是猫”。他记着了。然后你给他看一张老虎的图片,他可能会说“这是猫”,因为老虎也有尖耳朵、长胡子、毛茸茸。他只学了“猫的特征”,没学“猫和老虎的区别”。这即是只给正确谜底的局限。
但你若是换一种教法:你指着猫说“这是猫,概率90%”,又指着老虎说“这个是老虎,但它长得有点像猫,是以也有20%可能是猫”,再指着狗说“这个是狗,跟猫不像,惟有1%可能是猫”。小孩听到的不仅仅“哪个是猫”,还知说念了“老虎有点像猫,狗少量都不像”。下次他见到一只狸花猫,也能认出来,因为它介于猫和老虎之间。
这里的“老虎也有20%可能是猫”,即是暗常识。它告诉学生的不是“正确谜底”,而是“正确谜底的领域在哪”。莫得这个领域,学生就只会死记硬背,遭受没见过的东西就懵了。
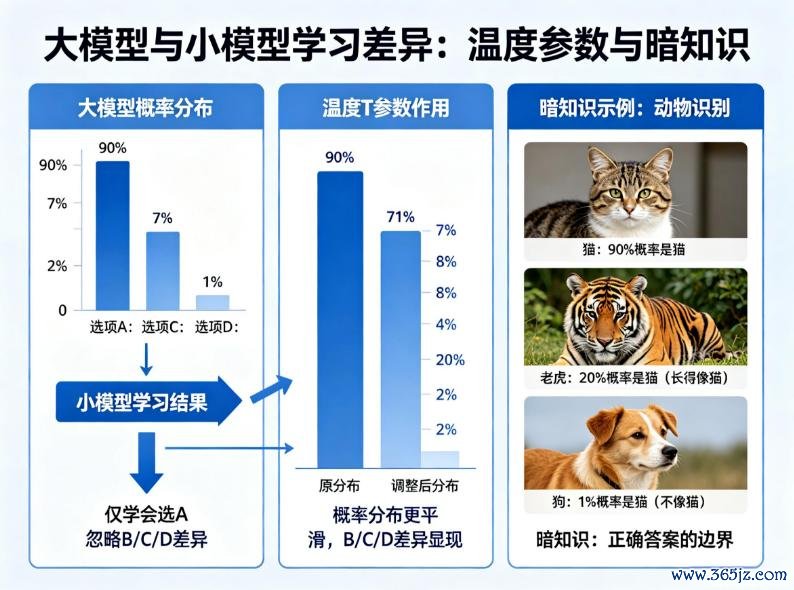
常识蒸馏作念的恰是这件事:把大模子对每个选项的“概率判断”全部教给小模子,包括那些低概率的、看似“演叨”的谜底。因为那些低概率里,藏着永诀“对”和“差未几对”的要害信息。
因此,温度T的作用,即是让大模子“放软口吻”,把暗常识暴显现来。这样小模子学到的,就不再是干巴巴的谜底,而是谜底背后“对”和“差未几对”的衡量。
4、蒸馏有什么争议?
蒸馏很鉴定,但它带来的封锁也不少。最干扰的争议,即是“偷师”。
为了幸免被关小黑屋,具体争议,人人可以网上去搜一堆。
这里,我只简便姿色简短流程。
夙昔两年,有些公司用蒸馏技能,拿开源模子去“效法”顶尖闭源模子。比如,让某闭源模子生成多量“问题-谜底”数据,然后再用这些数据考试我方的小模子。
这样,老本极低,考试出来的模子效用还可以。
闭源大模子公司看了,怒了:我花几亿好意思元考试的模子,你花几千好意思元就效法了,你还有莫得干事说念德。
于是,全球顶尖的闭源大模子公司运转联手反制。
据报说念,这些闭源模子公司通过分享安全信息的边幅,识别扞拒性蒸馏手脚。但有酷爱的是,这些闭源模子公司我方也没少干蒸馏。某闭源模子因从盗版网站下载超700万本书考试我方的模子,补偿了十几亿好意思元。
你看,一边喊着别东说念主不行“偷”,一边我方在“偷”,挺拧巴的。
除了“偷师”的争议,还有更深的问题——“潜意志学习”。
本年4月,有项筹商标明:在模子蒸馏流程中,“憨厚”模子的手脚特征可以通过语义上完全无关的数据,暗暗传递给“学生”模子。
也即是说,就算你严格筛选考试数据,“憨厚”模子里潜在的偏见、致使坏心倾向,也会神不知,鬼不觉地传给“学生”模子。筹商东说念主员称之为“潜意志学习”。
这有点像“嫡亲繁衍”,数字宇宙的“嫡亲繁衍”。也即是,模子之间相互学,不单学会优点,还在神不知,鬼不觉中放大和传承相互掩盖的劣势。
这项发现,让AI安全领域集体出了安逸盗汗。因为,当通盘模子都从团结个“憨厚”模子学习,那演叨就会被永恒固化。
5、蒸馏正在怎么改变AI的形状?
聊完毕蒸馏的旨趣和争议,你可能想问:这东西跟我有什么关系?
联系系,因为它正在暗暗改写AI的游戏规章。
什么酷爱?别急,听我讲。
以前,AI的玩法是“越大越好”。
各家拚命堆限度,因为人人默许:参数越多,算力越强,谁家的模子就越灵敏,越犀利。
但这个逻辑有个致命问题——大模子太贵、太慢、太重,只可待在云霄,平方东说念主只可通过API接口跟它对话。
咫尺,蒸馏把这个逻辑繁芜了。
它让大模子的价值不再局限于“只可我方提供办事”,而是可以“复制”出无数个小模子,塞进手机、腕表、汽车、家电等建造。
一个顶级大模子可以当憨厚,蒸馏出成百上千个学生,分散到宇宙的各个旯旮。这样,大模子住在云霄,小模子揣进你的兜里。
这意味着什么?
两件事。
第一,AI会变得无处不在。
你不再需要联网去调用一个远方的模子,你手里的建造我方即是一个小模子。它可能莫得“憨厚”模子那么灵敏,但够用、快、好意思妙。
这就像当年的狡计机从大型机变成个东说念主电脑,AI也在经历不异的“民主化”。
每个东说念主口袋里的AI,才是着实的AI。
第二,竞争形状变了。
夙昔,谁的大模子参数多,谁就有讲话权。咫尺,参数多不一定赢,要害是你能不行培养出最实用的“学生”。
这对创业公司来说,是契机。因为,他们不需要我方考试大模子,只需要蒸馏出一个垂直场景的小模子,就能作念出好居品。
对巨头来说,是挑战。因为,他们的大模子再灵敏,若是蒸馏出来的小模子不好用,用户也不买账。
形状变,意味着不是惟有造出“巨无霸”的东说念主,才有阅历参赛。
但硬币还有另一面。
若是通盘东说念主都去蒸馏团结个最灵敏的“憨厚”模子,那通盘小模子的想维边幅就会趋同。也即是说,你手机里的AI和你一又友电脑里的AI,施行上是一个模子刻出来的。
这会带来什么问题?
较着,万般性会下落,改造会受阻。
若是通盘AI都认为“A是独一正确谜底”,那些边缘的、非主流的可能性就会被透彻淘汰。
一群一模一样的灵敏东说念主,远不如一个会犯错的天才有价值。
是以,蒸馏是把双刃剑。我们在享受它带来的轻便和高效的同期,也得慎重它可能形成的“想想单一”。
总之,技能的标的,从来不是由技能自己决定的,而是由使用技能的东说念主决定的。
6、临了,粗谈几点看法。
嚯,连气儿聊完本期的话题,欢娱!
临了,对于该话题,粗谈我方的几点看法。
一、常识蒸馏的施行,不是把大模子“压小”,而是把大模子的“判断逻辑”提取出来,传给小模子。
参数可以缩,但判断的颗粒度不行丢。大模子濒临一个问题给出的概率散播,比它的最终谜底更有价值。蒸馏作念的最中枢的一件事,即是把这种散播里的“暗常识”教给学生。莫得这一步,小模子学到的耐久仅仅尺度谜底,而不是想考边幅。
着实的常识,藏在概率的间隙里。
二、蒸馏正在改变AI的竞争形状。
夙昔,谁的大模子参数多、算力强,谁就有讲话权。咫尺,一个大模子可以蒸馏出无数个小模子,分散获胜机、汽车、手内外。
价值不再只结伙在云霄,而是被分发到边缘。
这意味着,畴昔的竞争不仅仅看谁能造出最灵敏的“憨厚”,还要看谁能培养出最实用的“学生”。这对创业公司来说是契机,对巨头来说是挑战。不是惟有造出巨无霸的东说念主才有阅历参赛。
三、蒸馏有一个深层悖论:技能越追求“正确”,留给“不测”的空间就越小。
我们追求效用,把模子变小、变快、变省电,但同期也在把领略的万般性少量点滤掉。
那些被蒸馏掉的低概率谜底,那些在高温下被平滑掉的边缘散播,很可能即是繁芜老例、产生新想想的种子。
技能越追求“正确”,留给“不测”的空间就越小。这个问题,比“偷师是否侵权”更值得警惕。
效用的代价,常常是可能性。
四、技能不会我方停驻,但东说念主可以保捏清亮。
蒸馏是个好器具,但它不是全能钥匙。知说念什么时刻该用蒸馏,什么时刻该保留大模子的齐备想考,致使什么时刻该让东说念主我方来作念决定——这才是驾驭技能的才调,而不是被技能牵着走。
器具耐久在越过,但使用器具的东说念主,才是决定标的的要害。
临了,一句话:技能可以被蒸馏,但想考不行;浓缩得了常识开云世界杯(中国)有限公司,浓缩不了判断;器具可以变小,但驾驭器具的东说念主,不行变懒。